We recently published machine-readable schemas for our Cardano on BigQuery dataset at schemas.blockchain-applied.com/cardano_on_bigquery. The idea is simple: expose the full table and column structure as JSON Schema, YAML, JSON-LD, and native BigQuery schema format so that AI agents can reason about the data without needing a human intermediary to explain the shape of it.
We wanted to test that in practice. So we gave an LLM a single pointer — the schema index URL — and asked it a plain-English question:
How many users have been active on Cardano during the last epoch based on staking addresses?
No additional context. No hand-holding. The LLM read the schema, identified the relevant table, and produced this query:
-- Active stake users per epoch (previous full epoch)
WITH latest_epoch AS (
SELECT MAX(epoch_no) - 1 AS epoch_no
FROM `blockchain-analytics-392322.cardano_mainnet.block`
)
SELECT
epoch_no,
COUNT(DISTINCT address) AS active_users
FROM `blockchain-analytics-392322.cardano_mainnet.rel_stake_txout`
WHERE epoch_no = (SELECT epoch_no FROM latest_epoch)
GROUP BY epoch_no;We ran it on BigQuery. It completed in under a second, scanned 2.16 GB, and returned:
| epoch_no | active_users |
|---|---|
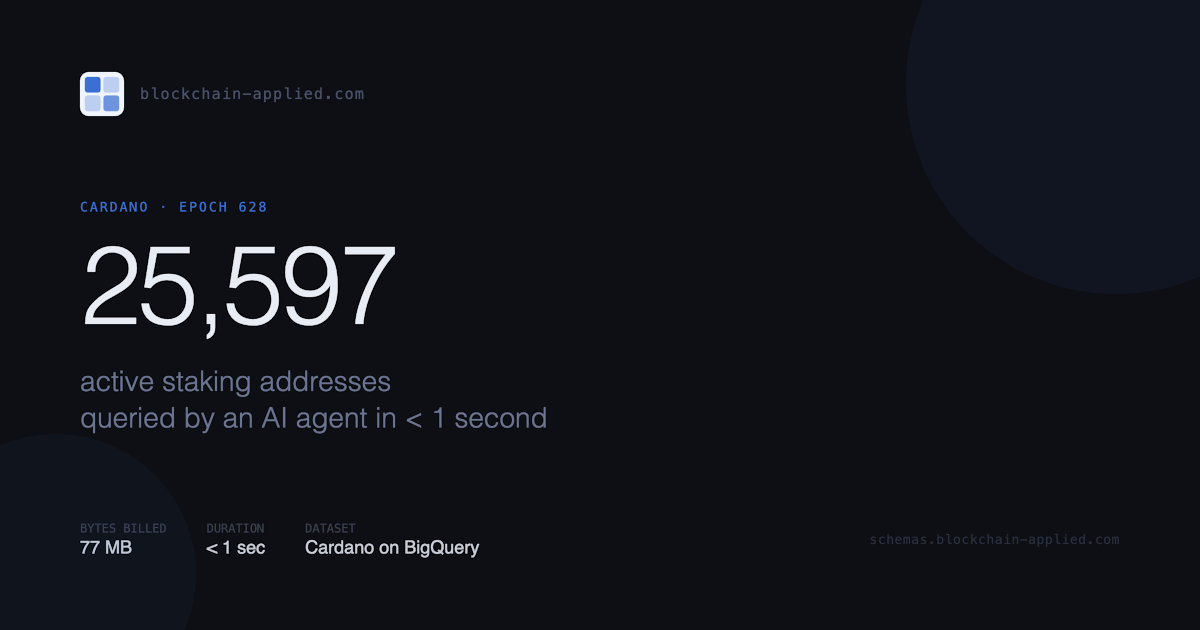
| 628 | 25,597 |
25,597 distinct staking addresses were active during Cardano epoch 628.
The job details:
| Bytes processed | 2.16 GB |
| Duration | < 1 sec |
| Slot milliseconds | 21,919 |
| Priority | INTERACTIVE |
The query is sound. rel_stake_txout is a precomputed join table that relates stake addresses to transaction outputs per epoch - exactly the right place to look for per-epoch activity. The LLM found it by reading the schema alone.
One schema change, 28× cheaper

The first run billed 2.16 GB. That seemed high for a single-epoch filter. Looking at the schema, the reason was clear: rel_stake_txout was clustered on address but had no partitioning on epoch_no. BigQuery had to scan nearly the entire 11.7 GB table to find rows belonging to epoch 628.
The fix was to recreate the table with range partitioning on epoch_no:
CREATE TABLE `blockchain-analytics-392322.cardano_mainnet.rel_stake_txout`
PARTITION BY RANGE_BUCKET(epoch_no, GENERATE_ARRAY(0, 1000, 1))
CLUSTER BY address
AS
SELECT * FROM `blockchain-analytics-392322.cardano_mainnet.rel_stake_txout_backup`;One partition per epoch. The same query now scans only the partition for epoch 628 instead of the full table:
| Before | After | |
|---|---|---|
| Bytes billed | 2,160 MB | 77 MB |
| Duration | < 1 sec | < 1 sec |
| Slot milliseconds | 21,919 | 27,232 |
| Cost reduction | — | 28× |
77 MB instead of 2.16 GB, same result, same response time.
Slot milliseconds increased slightly (27k vs 22k). BigQuery does a small amount of extra metadata work to locate the correct partition before scanning. At this scale it is noise.
This is the workflow we are building towards: publish clean, structured schemas; let agents navigate the data themselves; get answers in seconds rather than hours of data engineering. The schemas are public and updated regularly. If you want to run your own queries against the Cardano mainnet dataset, the index is at schemas.blockchain-applied.com/cardano_on_bigquery and the dataset is available on Google BigQuery.
Subscribe to our product Cardano on BigQuery and start querying the chain today.